0. Resumen
1. Introducción a Apache Hadoop
2. Almacenamiento y procesamiento en Hadoop
3. Ecosistema Hadoop
4. Administración y monitorización de sistemas
5. Aplicación práctica de tecnologías Big Data
Tarjetas
| Pregunta | Respuesta |
| ¿Cuál es la definición principal de Apache Hadoop? | Es una plataforma de código abierto que permite almacenar y procesar grandes volúmenes de datos de forma distribuida y escalable. |
| ¿En qué dos publicaciones de Google se inspiró inicialmente el desarrollo de Hadoop? | Google File System y MapReduce. |
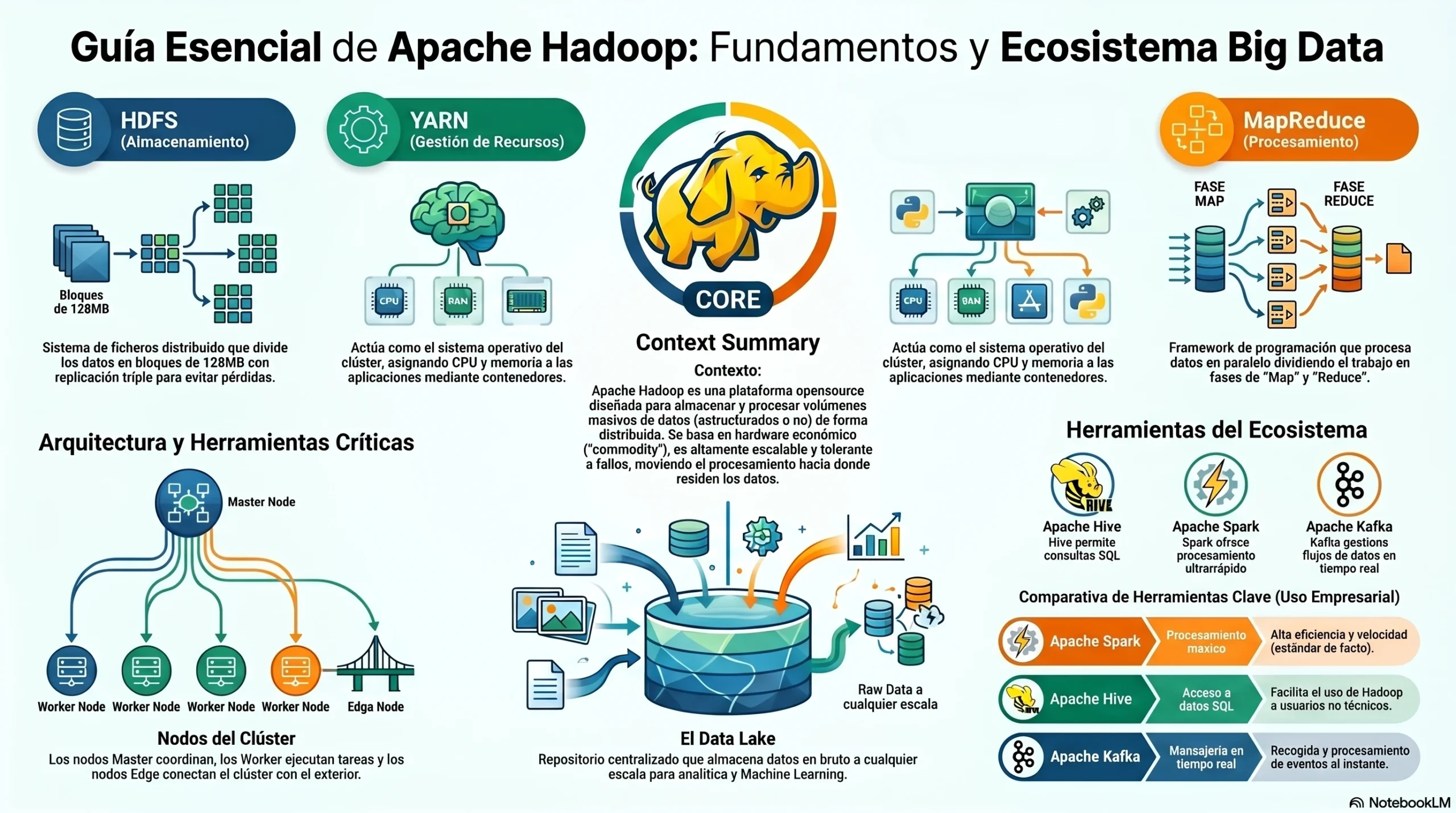
| Menciona los dos componentes fundamentales del ‘core’ de Hadoop. | HDFS y YARN. |
| ¿Qué es HDFS dentro del ecosistema de Hadoop? | Es la capa de almacenamiento distribuido basada en espacios de nombres. |
| ¿Cuál es la función principal de YARN en un clúster de Hadoop? | Gestionar los recursos y los procesos que se ejecutan en el clúster. |
| ¿Qué paradigma utiliza Hadoop para mejorar la eficiencia del procesamiento? | El acercamiento del procesamiento a los datos. |
| ¿A qué se refiere el término ‘hardware commodity’ en el contexto de Hadoop? | Al uso de servidores estándar o convencionales en lugar de equipos especializados y costosos. |
| ¿Cómo se denomina al conjunto de servidores que trabajan coordinados para implementar las funcionalidades de Hadoop? | Clúster |
| ¿Qué función cumplen los ‘nodos worker’ en un clúster? | Realizar las tareas de almacenamiento y ejecución de trabajos. |
| ¿Cuál es la responsabilidad de los ‘nodos master’? | Controlar la ejecución de trabajos, el almacenamiento de datos y vigilar el estado de los nodos worker. |
| ¿Qué papel desempeñan los ‘nodos edge’ o frontera? | Actuar como puente entre el clúster y la red exterior, proporcionando interfaces y APIs. |
| ¿Por qué los nodos master suelen usar configuraciones de disco en RAID? | Para garantizar la redundancia de datos críticos del clúster y aumentar la resistencia a fallos. |
| En los nodos worker, ¿qué significa la configuración de discos JBOD? | Que cada disco es independiente y suma su capacidad a la general del nodo sin replicación a nivel de hardware. |
| ¿Qué ventaja ofrece una distribución comercial de Hadoop frente a la versión puramente opensource? | Incluye un instalador simplificado, resolución de dependencias y soporte empresarial 24×7. |
| ¿Qué nombre recibe el efecto de dependencia hacia un proveedor cloud en Hadoop-as-a-Service? | Vendor lock-in |
| ¿Cuál es el tamaño por defecto de los bloques de datos en HDFS? | 128 megabytes |
| ¿Qué característica de HDFS garantiza que no se pierdan datos ante el fallo de un nodo? | La replicación de bloques (habitualmente por un factor de 3). |
| ¿A qué se refiere la orientación ‘write-once, read-many’ de HDFS? | A que los archivos se escriben una vez y no se modifican, aunque se pueden leer múltiples veces. |
| ¿Qué componente de HDFS es el encargado de almacenar los metadatos y actuar como maestro? | Namenode |
| ¿Cuál es la función del Secondary Namenode en HDFS? | Facilitar el proceso de arranque del Namenode almacenando instantáneas del estado del sistema de ficheros. |
| ¿Qué componente de HDFS almacena físicamente los bloques de los archivos? | Datanode |
| ¿Qué sucede en HDFS si un Datanode falla? | El sistema sigue funcionando correctamente y los datos se recuperan de las réplicas en otros nodos. |
| Comando de HDFS: `mkdir` | Se utiliza para crear directorios dentro del sistema de archivos distribuido. |
| Comando de HDFS: `put` o `copyFromLocal` | Copia archivos desde el sistema de archivos local hacia HDFS. |
| Comando de HDFS: `get` o `copyToLocal` | Copia archivos desde HDFS hacia el sistema de archivos local. |
| ¿Para qué sirve el comando `setrep` en HDFS? | Para modificar manualmente el factor de replicación de un fichero o directorio específico. |
| ¿Cuál es el protocolo utilizado por la API REST de HDFS para acceder desde distintos lenguajes? | WebHDFS |
| En YARN, ¿qué es un ‘contenedor’? | Es la unidad mínima de recursos (CPU y memoria) asignada para ejecutar una tarea. |
| ¿Qué componente de YARN es el responsable de coordinar la ejecución de trabajos a nivel global del clúster? | ResourceManager |
| ¿Cómo detecta YARN el fallo de un nodo durante la ejecución de una tarea? | Mediante la monitorización continua, lo que le permite relanzar la tarea fallida en otro nodo activo. |
| Menciona las cinco etapas de un trabajo en MapReduce. | Envío, Map, Shuffle, Order y Reduce. |
| ¿Qué fases de MapReduce suele programar el desarrollador manualmente? | Las fases de Map y Reduce. |
| Concepto: Apache Hive | Herramienta que permite acceder a datos en HDFS mediante un lenguaje similar a SQL llamado HQL. |
| Concepto: Apache Spark | Motor de procesamiento masivo de datos en paralelo que se ha convertido en el estándar de facto para Big Data. |
| ¿Qué es un RDD en el contexto de Apache Spark? | Es la principal abstracción de datos para el procesamiento distribuido. |
| Concepto: Apache HBase | Base de datos NoSQL de tipo columnar que permite el acceso aleatorio y atómico a los datos sobre HDFS. |
| ¿Cuál es la función de Apache Sqoop? | Transferir datos de forma eficiente entre Hadoop y bases de datos relacionales. |
| ¿Qué herramienta se utiliza para la ingesta de streams de datos o ‘logs’ en tiempo real? | Apache Flume |
| ¿Cuál es el propósito de Apache Oozie? | Orquestar y planificar flujos de trabajo (workflows) dentro del clúster de Hadoop. |
| Concepto: Apache Ambari | Herramienta para el aprovisionamiento, gestión y monitorización de clústeres Hadoop mediante una interfaz visual. |
| ¿Qué diferencia a Apache Impala de Apache Hive? | Impala está implementada en un lenguaje de más bajo nivel y ofrece un rendimiento superior para consultas SQL. |
| ¿Qué rol se encarga de realizar la ingesta de datos en crudo y procesarlos para su análisis posterior? | Ingeniero de datos (Data Engineer) |
| ¿Qué rol utiliza técnicas de Inteligencia Artificial para crear modelos predictivos? | Científico de datos (Data Scientist) |
| ¿En qué directorio suelen encontrarse los ficheros de configuración de Hadoop? | `/etc/conf` |
| ¿Qué propiedad del fichero `core-site.xml` indica el ‘endpoint’ de HDFS para los clientes? | `fs.defaultFS` |
| ¿Para qué sirve el parámetro `dfs.datanode.data.dir` en el fichero `hdfs-site.xml`? | Indica el directorio local en el nodo worker donde se almacenan físicamente los bloques de HDFS. |
| ¿Cuáles son los tres posibles motores de ejecución que se pueden configurar en Hive? | MapReduce, Tez y Spark. |
| ¿Qué comando de Linux se utiliza comúnmente para monitorizar el uso de CPU en tiempo real? | `top` |
| ¿Qué interfaz web permite ver el espacio ocupado en HDFS y navegar por sus ficheros? | Namenode UI (puerto 50070 por defecto). |
| ¿Qué utilidad tiene la opción ‘Scheduler’ en la interfaz del ResourceManager de YARN? | Muestra el estado, capacidad y ocupación de las colas de ejecución configuradas. |
| ¿Qué es Ganglia? | Una herramienta de código abierto para la recogida de métricas y monitorización de clústeres de servidores. |
| En Ganglia, ¿qué hace el demonio `gmond`? | Se ejecuta en cada nodo para recopilar sus métricas y enviarlas al resto de nodos del clúster. |
| ¿Qué es un Data Lake? | Un repositorio centralizado que almacena todos los datos de una empresa (estructurados y no estructurados) a cualquier escala sin modificarlos previamente. |
| ¿Cómo se denominan los datos guardados en el Data Lake tal cual se reciben de la fuente? | Raw Data (Datos en crudo) |
| ¿Cuál es la principal ventaja de un Data Lake frente a un Datawarehouse tradicional? | Permite tomar todos los datos para el análisis sin necesidad de estructurarlos o filtrarlos previamente mediante procesos ETL rígidos. |
| Menciona las cuatro capas lógicas del modelo de un Data Lake. | Ingesta, Procesamiento, Repositorio e Insights. |
| ¿Qué caracteriza a una arquitectura de tipo ‘Data Mesh’? | Es un enfoque descentralizado donde cada dominio de negocio es responsable de sus propios datos y los ofrece como un producto. |
| ¿Cuál es uno de los problemas de escalar un Data Lake centralizado? | La generación de dependencias críticas sobre un único equipo central de ingeniería de datos. |
| ¿Qué es un ‘Data Swamp’? | Un repositorio de datos que carece de gobierno, metadatos y calidad, volviéndolo inútil para el análisis. |
| Concepto: Gobierno de Datos (Data Governance) | Conjunto de procesos y políticas que garantizan el uso eficiente, seguro y efectivo de los datos en una empresa. |
| ¿En qué consiste el principio de ‘Datos como Producto’ en Data Mesh? | En que los equipos de dominio deben ofrecer sus datos analíticos pensando en la facilidad de consumo para otros usuarios. |
| ¿Qué servicio de Amazon Web Services permite crear clústeres Hadoop a demanda? | Amazon EMR (Elastic MapReduce) |
| ¿Qué solución de Microsoft Azure ofrece Hadoop como servicio en modalidad de pago por uso? | Azure HDInsight |
| ¿Qué herramienta de administración utiliza HDInsight que no está presente de forma nativa en Amazon EMR? | Apache Ambari |
| ¿Cuál es el coste aproximado por nodo y hora de las soluciones Hadoop en la nube? | Entre $0,25$ y $2$ euros. |